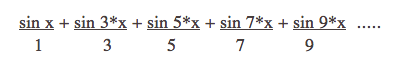You can put this cylindrical lens (3 equivalent forms shown) in the beam of a projector and turn height into luminance. For instance, this horizontal slot, whose width is modulated sinusoidally (top half of Figure below), can be turned into a sinusoidal grating (bottom half of Figure) by making a slide, projecting it, and smearing the projector’s beam of light vertically with the cylindrical lens.
You can put this cylindrical lens (3 equivalent forms shown) in the beam of a projector and turn height into luminance. For instance, this horizontal slot, whose width is modulated sinusoidally (top half of Figure below), can be turned into a sinusoidal grating (bottom half of Figure) by making a slide, projecting it, and smearing the projector’s beam of light vertically with the cylindrical lens.


This slide demonstrates that the cylindrical lens converts bar height into luminance. When smeared vertically, both bars are the same length (very long) but the longer bar (on the right) is much brighter because it contains more luminous flux.

Each horizontal slot is modulated sinusoidally in height. Having many slots just increases overall brightness.
Result: A sinusoidal grating.
 A frequency-swept sinusoidal grating. Low spatial frequency on the left, high spatial frequency on the right.
A frequency-swept sinusoidal grating. Low spatial frequency on the left, high spatial frequency on the right.
 When smeared vertically this creates the sharp edged vertical bars of a square wave grating! This demonstrates the Fourier components of a square wave, with relative frequencies 1, 3, 5, 7, 9… and relative amplitudes 1/1, 1/3, 1/5, 1/7, 1/9….
When smeared vertically this creates the sharp edged vertical bars of a square wave grating! This demonstrates the Fourier components of a square wave, with relative frequencies 1, 3, 5, 7, 9… and relative amplitudes 1/1, 1/3, 1/5, 1/7, 1/9….

A Craik-O’Brien-Cornsweet edge. The left and right regions have the same luminance but the spur-shaped luminance profile makes the right half look brighter.

Components of a Cornsweet edge are a sharp spatial step in luminance, which is very visible, plus a gradual spatial luminance ramp in the other direction, which is much less visible because the visual system is insensitive to low spatial frequencies.
How does a computer reconstitute X-ray slices to make a CAT scan? or MRI scan? Oscar Estevez (U of Amsterdam) shows this demonstration to his medical students: He rotates the cylindrical lens slowly in its own plane (around the axis of the projector beam). When the smear direction lines up with one edge of the triangle, a luminance edge appears in the smear. Smart students can guess from this that the target slide is a triangle. And a computer can guess that a target object is a brain.


 Below: HIRO ITO recorded eye movements tracking the chopstick stimulus with and without a surrounding frame.
Below: HIRO ITO recorded eye movements tracking the chopstick stimulus with and without a surrounding frame.